Eluvio Introduces Inline Frame-Accurate Video Intelligence and Next-Gen Eluvio Video Intelligence Editor (EVIE) with New Advanced AI Tools for Agentic Orchestration of Title Libraries and Live Sports at NAB 2026
Eluvio (https://eluv.io) today unveiled a major new architecture for Universal & Dynamic Video Intelligence and next-gen Eluvio Video Intelligence Editor (EVIE) with new Advanced AI Tools for agentic orchestration of title libraries and live sports ahead of the NAB Show 2026. Eluvio AI is the first commercially available solution that runs AI analysis and inference inline within the streaming media generation and distribution pipeline, producing frame accurate, fully-aligned textual and multi-modal labels, embeddings,and metadata, for both live and VOD content, and harnesses AI data just-in-time, enabling unlimited AI personalization and transformation of video, audio and image content.
This first-of-its-kind implementation operates with zero file copies, zero file movement, and zero re-transcoding at every stage: analysis, metadata generation, derivative creation, and delivery. It is a new architectural foundation for AI usage in live sports, events, studio archives, and other premium video use cases worldwide. Eluvio also opened registration for its exclusive NAB keynotes and demonstrations at https://nab.eluv.io.
Key benefits for users are personalization and re-monetization enabled by :
- Multi-modal, frame-accurate deep analysis and search (video, audio, text, images, and pose);
- Unmatched efficiency compared to other video AI workflows with zero file copies, file movement, or re-transcoding;
- Unlimited Runtime API and Vector/Tag Stores (with 15+ built-in models and processors) and fully open for continuous addition of the state-of-the-art without changing workflows or moving media;
- Real-time inline inference in LIVE streams as well as VoD content;
- Fully private ground truth, training, model configuration, and content protection with Content Fabric owner-controlled security and fine-grained permissions;
- Leveraging AI together with existing metadata for titles, play-by-play, and telemetry.
- Unlimited generative power for creating high quality vertical video from 16:9, and suggesting highlights, shorts and more from your content using the zero-copy JIT features of the Content Fabric.
- Multi-agent orchestration APIs for bringing it all together behind natural language prompts, 3rd party chatbots, and agentic interfaces.
- Frame-Accurate & Multi-Modal — Video, Audio, Text, Images, Multi-D Telemetry: Provides inference at frame and segment level across video, audio, text, images, and multi-dimensional telemetry with no secondary alignment step, a prerequisite for state-of-the art video analysis and AI implementation.
- Unmatched Efficiency: Zero Copy, No File Movement, No Transcoding: All inference and derivative creation occur within the Fabric by reference against original media parts. Derived playables are references to the original source, not new files, regardless of the number of variants produced as output.
- Unlimited Runtime API: Open source, custom, or 3rd party models — expands continuously with the state of the art. New models include Focus Detection & ID, Speaker Detection & ID, Custom Motion ID, OpenCLIP, ImageBind, and Eluvio-enhanced MediaPipe across image, video, and pose modalities.
- Real-Time Inline Inference: AI reads live content parts as published and writes tags back in real time with no re-transcoding; Demonstrated in production with custom models trained on expert ground-truth labels for live events/sports.
- Private Ground Truth Training: Customers build and deploy custom models trained on their own labeled content; Fully tenant-isolated and tamper-proof within the Fabric security model.
- Unlimited Generative Power: Highlights, trailers, shorts, social clips, chapters, synopses, and captions — all as zero-copy derived playables.
- Generative Processors / Multi-Agent APIs: Inline processors run on tags and embeddings to produce configurable summarization (synopsis, captions, social copy); chapter segmentation and labeling; topic, mood, and trope identification; compliance analysis by timecode; and zero-copy composition generation for social clips, trailers, highlights, and shorts; Natural language prompts personalize all outputs.
- Enhanced Multimodal Content Search: Natural language, image, and music search — plus frame-region queries via bounding boxes — returning matching video shots, scenes, clips, or frames; RAG-based retrieval with confidence scoring, protected by fine-grained Fabric permissions.
- MCP App for ChatGPT, Claude, and Other LLMs: A client-side MCP App enables complex multi-step agentic video workflows from a natural language chat interface. From a single prompt: run models, update vector indices, generate transcriptions and chapter highlights, and produce social-ready clips, a trailer, and a short — all zero-copy. All APIs are fully secured and tenant-authorized.
Latest IAMT News
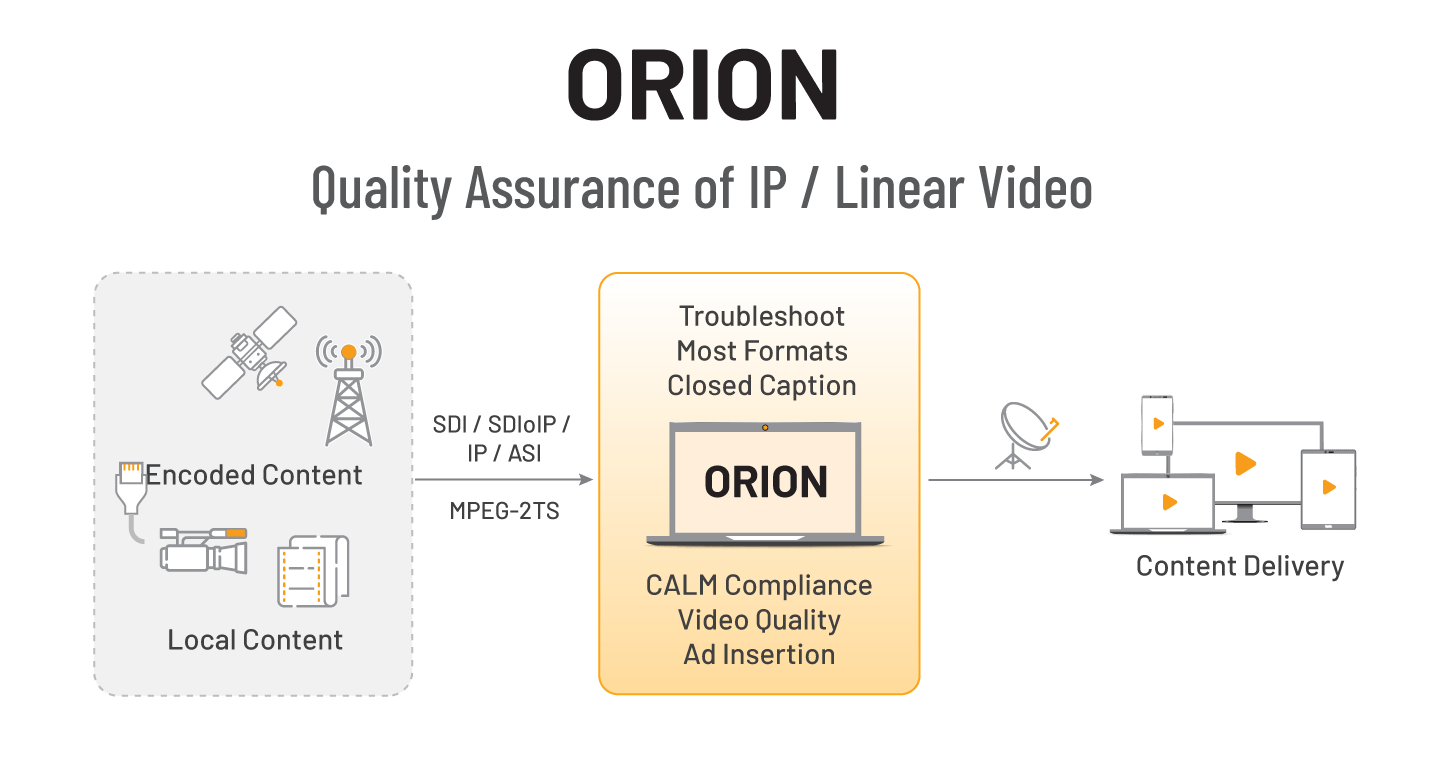
Interra Systems Enhances ORION With Stream Recording and BATON Media Player Integration for Advanced Debugging

Astro selects Broadpeak for high performance streaming and CDN solutions in pay-TV transformation
Sign-Up Here
Industry news, event updates and more. Sign-up for the IAMT Newsletter.

