NStarX – Context Graphs: The Next Frontier for Media Intelligence

Sujay Kumar, Chief Revenue Officer, NStarX Inc.
There’s a conversation happening in boardrooms and tech suites across the media industry right now, and it almost always starts the same way: “We have all this content. Why can’t we find it, use it, or monetize it properly?”
The answer isn’t a lack of data. Broadcasters and media companies are sitting on decades of archives, audience behavioral signals, rights databases, scheduling logs, and increasingly, AI-generated metadata. The problem is that none of it talks to each other. It lives in silos — editorial systems disconnected from rights management, audience data isolated from content catalogs, GenAI outputs floating free of any structured context. The result is fragmentation at scale, and it’s costing the industry both revenue and relevance.
Context Graphs are emerging as the architectural answer to that fragmentation — and the timing couldn’t be more critical.
What Exactly Is a Context Graph?
A Context Graph is a dynamic, interconnected knowledge structure that links entities — content assets, people, topics, rights windows, audience segments, locations, events — through meaningful, queryable relationships. Unlike a traditional database that stores information in rows and columns, a Context Graph stores it as a web of nodes and edges, where the relationships between things are as important as the things themselves.
Think of it this way: a database can tell you that a documentary about the 1966 World Cup exists in your archive. A Context Graph can tell you that the same documentary is related to an upcoming anniversary event, that it features three players whose estates hold clearance rights expiring in 18 months, that audience segments aged 45–65 in the UK and Germany show high affinity for this topic, and that two of your streaming competitors just licensed similar content last quarter.
That’s not just retrieval. That’s intelligence.
What distinguishes a Context Graph from a standard knowledge graph is the layering of real-time signals — audience behavior, market data, rights status, editorial calendars — on top of the structural ontology. It’s a living system, not a static index.
Unifying the Archive, Rights, Schedules, and Audience
For broadcasters, the practical value of a Context Graph starts with unification. Most media organizations operate with four or five core data domains that have grown independently: content management systems, rights and licensing platforms, scheduling and traffic systems, audience analytics, and increasingly, AI-generated tagging and enrichment layers. Each of these systems has its own schema, its own vendor, and its own version of truth.
A Context Graph doesn’t replace these systems. It federates them. By mapping entities across these domains and defining the semantic relationships between them — this asset belongs to this rights package, which is restricted in these territories, which corresponds to this audience cluster with high engagement probability during this daypart — you create a unified intelligence layer that sits above your existing infrastructure.
The moment that layer exists, a rights manager can search not just by title or format, but by commercial opportunity. A scheduler can see which archived content has untapped potential in markets where rights are still open. A content team can understand which topics are trending with specific audience segments before committing production spend.
The archive stops being a storage problem and starts being a revenue asset.
The Impact on Discovery, Rights Exploitation, and Monetization
The commercial case for Context Graphs is strongest in three areas.
Content discovery is the most immediate win. When your metadata is richly connected, AI-powered search stops returning flat keyword matches and starts surfacing contextually relevant results. A journalist looking for footage of “floods in Southeast Asia” doesn’t need to scroll through 800 untagged clips — the Context Graph understands that this footage relates to a climate event, connects it to related documentaries, flags the clearance status, and ranks results by audience relevance.
Rights exploitation is where broadcasters leave the most money on the table today. Rights windows open and close constantly across territories, platforms, and formats — and most organizations don’t have the visibility to act on them systematically. A Context Graph with integrated rights data creates an always-on opportunity layer. When a rights window opens in a new territory, the system can proactively surface matching content, flag production assets that could be localized, and estimate audience potential — turning passive rights ownership into active commercial strategy.
Monetization through personalization is the third lever. When audience signals are woven into the graph alongside content attributes, recommendations become genuinely contextual — not just “people who watched X also watched Y,” but a dynamic understanding of why content resonates with which audiences in which moments. That intelligence directly informs advertising, syndication pricing, and content investment decisions.
Building the Architecture: GenAI Meets Knowledge Graphs
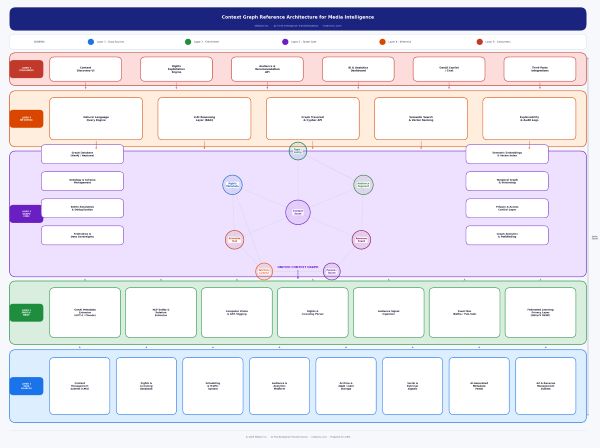
The practical architecture for a media Context Graph has three layers. The foundation is a graph database — Neo4j, Amazon Neptune, or similar — that holds your ontology: the defined entities and relationship types relevant to your business. The second layer is the enrichment pipeline, where GenAI models extract semantic meaning from unstructured content — transcripts, scripts, footage descriptions — and translate it into structured graph nodes and relationships at scale. The third layer is the inference and query interface, where large language models sit on top of the graph and allow natural language querying. Instead of building complex graph traversal queries, an analyst simply asks: “Which archive assets could generate licensing revenue in APAC before Q3?” and the system reasons across the graph to answer.
The key architectural principle is federation over centralization. At NStarX, we build these systems on federated learning foundations precisely because media organizations need intelligence that respects data sovereignty — particularly when rights data, audience data, and third-party signals are involved. Here is how a sample reference architecture (Figure 1) look like:
The Window Is Now
Media companies that build Context Graph capabilities in the next 18 months will have a structural advantage: they’ll be able to act on their data rather than just store it. The ones that don’t will continue to watch competitors license content they didn’t know they had, recommend programming they couldn’t find, and monetize audiences they couldn’t understand.
The content exists. The intelligence layer is what’s missing.
NStarX Inc. is an AI-first enterprise transformation company specializing in federated learning and privacy-preserving AI for media, healthcare, and financial services. Learn more at nstarxinc.com.
Latest IAMT News
Interra Systems Enhances ORION With Stream Recording and BATON Media Player Integration for Advanced Debugging

Astro selects Broadpeak for high performance streaming and CDN solutions in pay-TV transformation
Sign-Up Here
Industry news, event updates and more. Sign-up for the IAMT Newsletter.

